
HTML pages consist of a hierarchy of tags which can contain text. Consider the following page:
Which should appear in the browser as a table as follows:
|
Name |
Phone |
|
Smith |
(333) 222-1111 |
|
White |
(444) 333-2222 |
If we want to get the phone number of Mr. Smith, the WebQuery control uses the Microsoft MSHTML parser. The parser produces, from the above page, a hierarchical structure that looks like the following image:
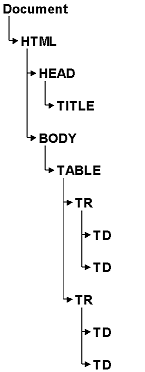
Each document consists of elements called nodes, not to be confused with entry nodes and exit nodes of a VBVoice control. Nodes have properties. The most common properties are attributes, which occur between the element's tag brackets. For example:
![]()
This tag generates an HTML node with a property named border with the value 1.
This property contains the text portion of the document that is enclosed by the node tags after stripping out all HTML tags and properties. For the above example, the InnerText of the element is the text Smith:
<TD>Smith</TD>
For the node that contains the <TD> node as a child:
<TR>
Its InnerText value is Smith(333)222-1111. Note that there is no white space between Smith and the number.
The InnerText property is the one used in search text between the WebQuery control and it is the value returned to the VB developer.
This property contains the portion of the HTML document that represents the element and all its children. For the previous two examples they are:
<TD>Smith</TD>
And
<TR>
<TD>Smith</TD>
<TD>(333)222-1111</TD>
</TR>
In most cases, pages are simple enough and ordered in such a way that no more parsing process is required. However, there might be some complicated pages and that is when InnerHTML property takes importance because it gives the developer more flexibility on handling the results received from the page.
This is an index to the nodes as they appear in the parser's result hierarchy. The parser usually creates this index so it is not really tied with the node.
Most of the pages contain dynamic contents and ads that are changed frequently. For that reason you cannot depend on the sourceIndex as it is to refer to a specific information that we want to retrieve, so WebQuery implemented a runtime property (its initial counterpart is INodeOffset) called NodeOffset which is the difference between the sourceIndexes of two nodes. Those two nodes are the one meeting the search criteria and the one being returned to the developer. And we return both the InnerText and InnerHTML properties of that second node.
This is a special property that tells the name of the HTML tag for that node. It is up to the VB developer to use it for extra filtering on the searched results.
This is the HTML tag name of the direct parent node of the search node. Also included for extra filtering the results.
Any attribute that is associated with the element is presented to the user to use it upon filtering a specific information.
An example of this attribute is id, which might be used in pages containing forms. Because the id attribute is always unique it is a good way to find certain information on the page if it is used. If you are designing the page, it is highly recommended that you use this property as criteria.
Another important attribute is href, which is useful for data retrieval. You can use its content if you want to issue another http request from its URL for cases where the contents are listed on several pages and you have to hit NEXT in order to browse each next page of results.